Comprehensive Detailed Explanation
From the case study:
Research division data for Productline2 is currently in CSV format in storage2.
Requirement: “All the Research division data in the lakehouses must be presented as managed tables in Lakehouse explorer.”
In Fabric lakehouses, managed tables are stored in Delta format inside the Tables folder.
Step 1: Reading the source
df = spark.read.format("csv") \
options(header="true", inferSchema="true") \
load("abfss://storage1.dfs.core.windows.net/files/productline2")
This correctly ingests the CSV source from ADLS Gen2.
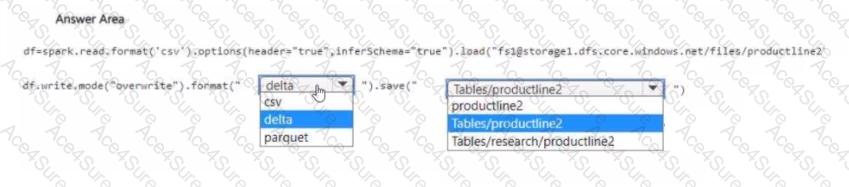
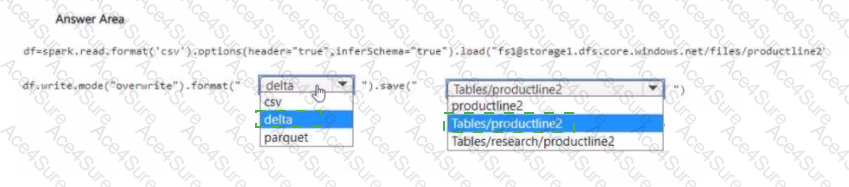
Step 2: Writing to Lakehouse as a managed table
You must write the data in Delta format to ensure it is queryable and managed within the lakehouse.
The correct path is under Tables/, because this is where Fabric automatically manages Lakehouse managed tables.
The target table should be named productline2, so the correct path is:
df.write.mode("overwrite").format("delta").save("Tables/productline2")
Why not other options?
CSV or Parquet formats would not create a managed Lakehouse table; they would just create files.
Writing to productline2 directly (without Tables/) would store unmanaged files in the Lakehouse Files area, not managed tables.
Writing to Tables/research/productline2 adds an unnecessary subdirectory and is not the standard structure for managed tables.
Correct Final Code
df.write.mode("overwrite").format("delta").save("Tables/productline2")
References
Managed tables in Microsoft Fabric Lakehouse
Delta Lake support in Fabric
Spark write to Lakehouse