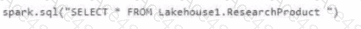Comprehensive Detailed Explanation
The question asks: Which syntax should you use in a Fabric notebook to access the Research division data for Productline1?
Key Background from the Case
In Productline1ws, a lakehouse named Lakehouse1 is created.
In Lakehouse1, a shortcut is created to storage1, named ResearchProduct.
Storage1 contains the Research division data for Productline1 in Delta format.
Requirement: All data in lakehouses must be presented as managed tables in Lakehouse explorer.
Analyzing the Syntax Options
Option A:
spark.sql("SELECT * FROM Lakehouse1.ResearchProduct")
This syntax directly queries the ResearchProduct shortcut within Lakehouse1 using Spark SQL.
Since the shortcut points to Delta data, Spark can directly query it.
This is the correct way to retrieve Productline1 data from Lakehouse1.
Option B:
spark.sql("SELECT * FROM Lakehouse1.productline1.ResearchProduct")
This introduces an extra schema-like path (productline1) that is not part of the shortcut name.
Incorrect, because the shortcut was created as ResearchProduct inside Lakehouse1, not under another schema.
Option C:
external_table('Tables/ResearchProduct')
external_table is not the correct way to access a Lakehouse shortcut.
Shortcuts in Lakehouses appear as tables and can be queried using Spark SQL directly.
Option D:
spark.sql("SELECT * FROM Lakehouse1.productline1.ResearchProduct")
Same issue as Option B, includes a schema path that does not exist.
Correct Choice
Since the shortcut to ResearchProduct was created inside Lakehouse1, and Spark SQL can query it directly, the correct syntax is:
spark.sql("SELECT * FROM Lakehouse1.ResearchProduct")
That matches Option A.
References
Microsoft Fabric Lakehouse – Shortcuts
Query data in a lakehouse using Spark SQL
Delta format support in Microsoft Fabric