Databricks Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Question Answer
A Spark developer wants to improve the performance of an existing PySpark UDF that runs a hash function that is not available in the standard Spark functions library. The existing UDF code is:
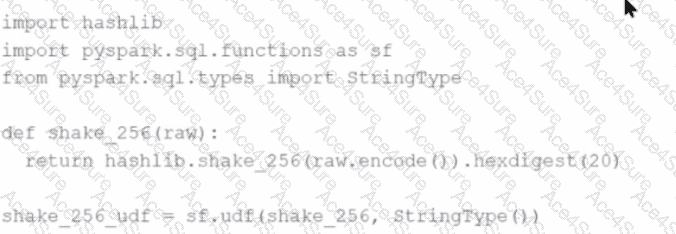
import hashlib
import pyspark.sql.functions as sf
from pyspark.sql.types import StringType
def shake_256(raw):
return hashlib.shake_256(raw.encode()).hexdigest(20)
shake_256_udf = sf.udf(shake_256, StringType())
The developer wants to replace this existing UDF with a Pandas UDF to improve performance. The developer changes the definition ofshake_256_udfto this:CopyEdit
shake_256_udf = sf.pandas_udf(shake_256, StringType())
However, the developer receives the error:
What should the signature of theshake_256()function be changed to in order to fix this error?
- Printable Format
- Value of Money
- 100% Pass Assurance
- Verified Answers
- Researched by Industry Experts
- Based on Real Exams Scenarios
- 100% Real Questions

