Databricks Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Question Answer
A data engineer wants to process a streaming DataFrame that receives sensor readings every second with columns sensor_id, temperature, and timestamp. The engineer needs to calculate the average temperature for each sensor over the last 5 minutes while the data is streaming.
Which code implementation achieves the requirement?
Options from the images provided:
A)

B)

C)
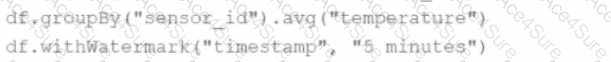
D)

Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 PDF/Engine
- Printable Format
- Value of Money
- 100% Pass Assurance
- Verified Answers
- Researched by Industry Experts
- Based on Real Exams Scenarios
- 100% Real Questions

Get 65% Discount on All Products,
Use Coupon: "ac4s65"
